
Kafka est de plus en plus utilisé dans nos entreprises et les projets intégrant des services de communication avec Kafka (Spring Kafka / Kafka Streams) se multiplient.
Nous avons donc besoin de rapidement monter un environnement de développement qui servira à la fois pour nos développements et pour nos tests.
Cet article, tout comme le premier How-To sur les starters Springboot, a pour but de vous faire gagner du temps sur la mise en oeuvre de votre environnement de développement.
🐳 Docker
Ci-dessous, vous trouverez la configuration du fichier compose.yaml permettant de monter une infra Confluent Kafka en local. Cette configuration permet de :
- Créer une instance Kafka en mode Kraft
- Initialiser un topic au démarrage
- Configurer un schéma AVRO sur le topic créé
services:
# https://docs.confluent.io/platform/current/installation/docker/config-reference.html#cp-kafka-example
kafka:
image: confluentinc/cp-kafka:latest
ports:
- "29092:29092"
- "29093:29093"
environment:
KAFKA_NODE_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:29093'
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@kafka:29093'
KAFKA_LISTENERS: 'PLAINTEXT://kafka:29092,CONTROLLER://kafka:29093,PLAINTEXT_HOST://0.0.0.0:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: 'MkU3OEVBNTcwNTJENDM2Qk'
KAFKA_LOG_CLEANUP_POLICY: 'compact'
### Uniquement pour créer les topics Kafka.
init-kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- kafka
entrypoint: [ '/bin/sh', '-c' ]
command: |
"
# blocks until kafka is reachable
echo -e 'Creating kafka topics'
kafka-topics --bootstrap-server kafka:29092 --create --if-not-exists --topic abonne-event --replication-factor 1 --partitions 1
echo -e 'Created kafka topics:'
kafka-topics --bootstrap-server kafka:29092 --list
"
environment:
# The following settings are listed here only to satisfy the image's requirements.
# We override the image's `command` anyways, hence this container will not start a broker.
KAFKA_BROKER_ID: ignored
KAFKA_ZOOKEEPER_CONNECT: ignored
schema-registry:
image: confluentinc/cp-schema-registry:latest
hostname: schema-registry
depends_on:
- kafka
ports:
- "28081:28081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: "kafka:29092"
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:28081
healthcheck:
test: [ "CMD", "curl", "--output", "/dev/null", "--silent", "--head", "--fail", "http://localhost:28081/subjects" ]
start_period: 3s
interval: 5s
timeout: 10s
retries: 10
# Permet de configurer un schema AVRO sur un topic
init-schema-registry:
container_name: init-schema-registry
image: badouralix/curl-jq:latest
depends_on:
schema-registry:
condition: service_healthy
command: [ "sh", "/tmp/scripts/init-schema.sh" ]
volumes:
- ./kafka-producer/target/avro/schema.avsc:/tmp/schema.avsc
- ./scripts/init-schema.sh:/tmp/scripts/init-schema.sh
healthcheck:
test: echo OK || exit 1
start_period: 3s
interval: 5s
timeout: 10s
retries: 3Configuration docker-compose.yaml
#!/usr/env/bin bash
# #########################
# add schemas to registry #
# #########################
# add schemas
jq '. | {schema: tojson}' /tmp/schema.avsc | curl -X POST --location 'http://schema-registry:28081/subjects/abonne-event-value/versions' --header 'Content-Type: application/vnd.schemaregistry.v1+json' --data @-script d'enregistrement du schéma
📤 Configuration d'un producer
Nous allons maintenant pouvoir configurer notre application de production de message :
spring:
kafka:
template:
observation-enabled: true
bootstrap-servers: localhost:29092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
compression-type: lz4
properties:
linger.ms: 20
auto.register.schemas: false
avro.remove.java.properties: true
properties:
security:
protocol: PLAINTEXT
schema:
registry:
url: http://localhost:28081application.yaml
📥 Configuration d'un consumer
Dans le cadre d'une application de consommation, la configuration ressemblera à :
spring:
kafka:
template:
observation-enabled: true
listener:
ack-mode: batch
concurrency: 1
type: batch
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
group-id: ${spring.application.name}
auto-offset-reset: earliest
properties:
specific.avro.reader: trueapplication.yaml
🔌 Plugin Kafka Intellij
Pour celles et ceux qui ont la chance d'avoir Intellij Ultimate, vous pouvez utiliser le plugin Kafka d'Intellij pour :
- Produire dans le topic consommé par l'application
- Consommer le topic dans lequel l'application produit des messages.
Dans notre cas, voici la configuration :
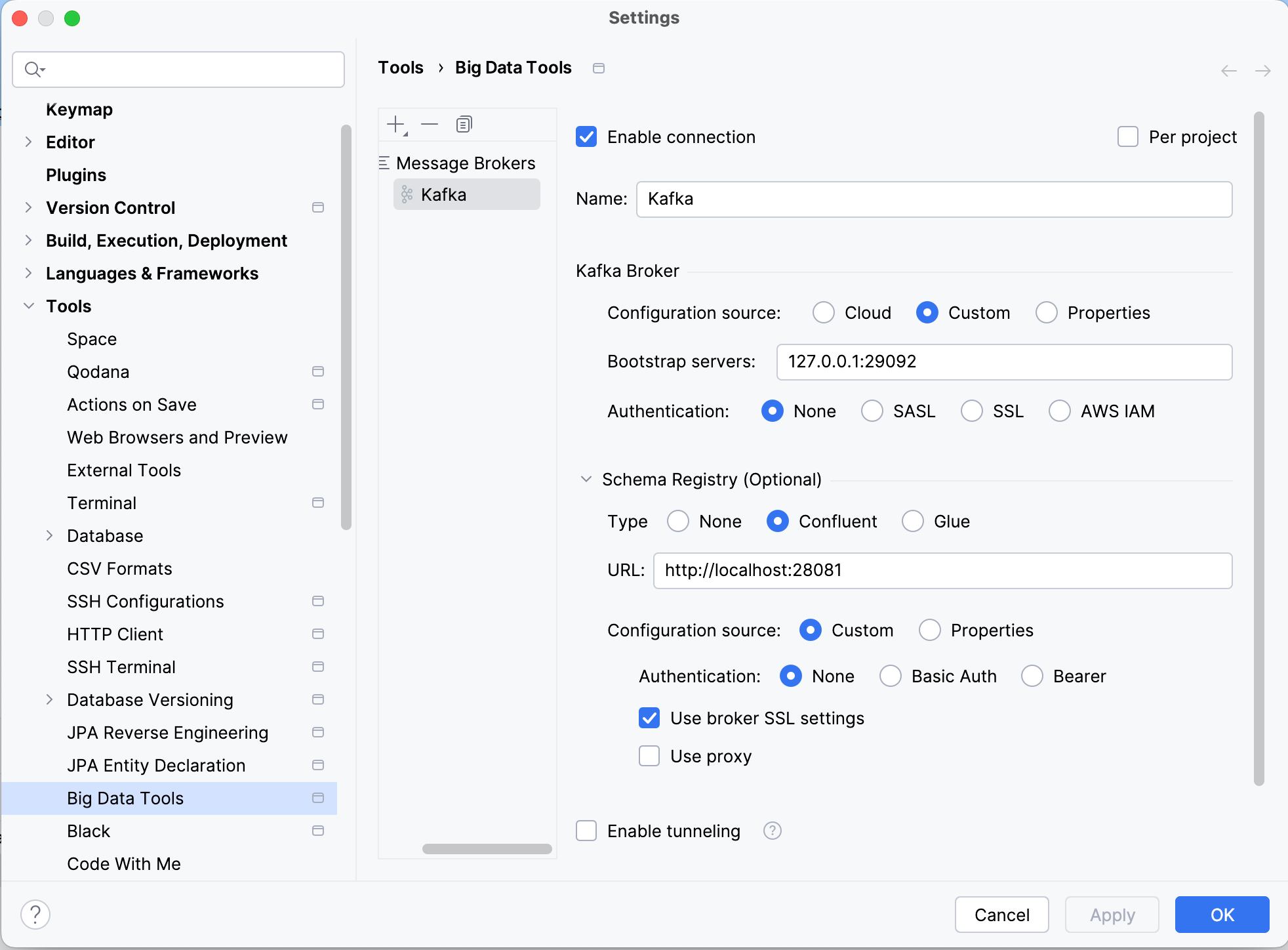
La documentation du plugin est disponible ici: https://plugins.jetbrains.com/plugin/21704-kafka
❤️ Rien que pour vous
Parce que des exemples valent mieux que milles mots, je vous partage mon repository Github contenant:
- Les configurations que nous venons de voir
- Une application de production
- Une application de consommation
- Des exemples de tests unitaires et tests d'intégrations
il est disponible ici: https://github.com/gfourny-sfeir/spring-kafka